ARM on Workforce Diversity Outcomes Record Dataset
Associate Rule Mining (ARM) on Workforce Diveristy Outcomes Record Dataset
1. Introduction
Associate rule mining (ARM) is concerned with associations between data items. ARM is an unsupervised machine learning method and is best used with categorical variables, so I am most concerned with the categorical record feature variables in my dataset. I want to find associations between seniority, gender, and ethnicity. There are seven levels of seniority, with 1 being the lowest and 7 being the highest (Revelio Labs, 2022). The dataset only has 2 levels of gender: male and female. Finally, there are six categories of ethnicity: ‘api’, ‘black’, ‘hispanic’, ‘multiple’, ‘native’, ‘white.’ I am not using the discrete variable ‘count’ or continuous variables ‘inflow,’ ‘outflow,’ and ‘salary,’ since ARM works best with categorical variables. Through my ARM analysis, I hope to uncover relationships between gender, ethnicity, and seniority in the six different public companies.
2. Theory
ARM is used to find associations between items in a set of transactions, or dataset. In particular, it is used for categorical data. ARM can be summarized in if-then statements; the “if” is also called an antecedent, while the “then” is also called a consequent. For example, we can find the association that “if a customer buys succulents, then they will purchase fertilizer”, which can be represented as {“succulents” –> “fertilizer”}; here, “succulents” is the “if” or antecedent, while “fertilizer” is the “then” or consequent. This association is directional, so one direction of the association may not hold true for the other direction (Remanan, 2018). In other words, the association “if X then Y” does not mean “if Y then X”.
Market basket analysis is a key application of ARM to uncover associations between items purchased by a customer. For example, if people purchase a sponge, they might purchase dish detergent as well since these are complementary cleaning household items. Learning about the strength of associations like this is helpful for companies to place products on aisles. It is important to note that ARM finds associations in a whole group rather than for a single identifier or customer, so we will not use this algorithm to, say, develop personal recommendations for a user given the user’s past purchasing baskets (Garg, 2018).
Defining several terms in ARM can help us understand ARM further. An itemset is a set of items described in a rule that can be partitioned into a binary “if” and “then”. A rule describes a directional association between items in an itemset. For example, {X, Y, Z} is an itemset while {X -> Y, Z} and {Y -> X, Z} are two example rules that could emerge from this itemset.
Furthermore, there are several concepts of ARM that are used to evaluate the strength of a rule: 1. Support is the fraction of data containing the itemset. Given itemset {X, Y}, Support(X and Y) = P(X and Y). 2. Confidence is the probability of occurrence of {Y} given {X} is present, or {Y|X}. Confidence(X -> Y) = P(X and Y) / P(X). 3. Lift is the ratio of confidence to baseline probability of occurrence of {Y}. Lift(X -> Y) = Support(X and Y) / (Support(X) * Support(Y)).
The apriori algorithm is one of many algorithms used for ARM. The apriori algorithm has two main steps: 1. Finds frequent itemsets with only 1 item. Frequent itemsets are defined as itemsets where support is greater than or equal to a minimum threshold, minsup. Apriori iterates this process to find frequent itemsets with only 2 items, then 3 items, and so on. Identifying frequent itemsets reduces the number of iterations apriori would have to perform in the next step. 2. Generates all permutations of “if” and “then” rules from the frequent itemsets. Apriori then prunes to find rules that have a confidence level above the minimum confidence level (minconf).
3. Methods
To conduct ARM, I first load necessary libraries and read the cleaned data. Then, I conducted further data cleaning by selecting the three relevant columns of gender, ethnicity, and seniority, convert them to string datatype, and then reformat them into a list of lists called ‘temp’ for the apriori algorithm. Each list in ‘temp’ contains 3 items––a given employee’s gender, ethnicity, and seniority.
Then, I defined three apriori utility functions referenced from Lab 6.1 led by Professor Nakul and Professor Hickman. The function reformat_results converts the apriori algorithm’s output into pandas dataframe with columns “rhs”, “lhs”, “supp”, “conf”, “supp x conf”, and “lift”. Specifically, The apropri model divides the data into LHS and RHS, which are the antecedent (“if”) and consequent (“then”). Then, the function convert_to_network() converts the dataframe to a network graph. Finally, the function plot_network() plots and visualizes the ARM network.
After defining these utility functions with global variables, I trained the ARM model on my data. I defined the parameters min_support, min_confidence, min_length, and max_length. In short, min_support is the minimum support or minsup variable mentioned in the previous subsection; the algorithm selects support values greater than the value specified in the parameter. Similarly, min_confidence is the minimum confidence or minconf variable and selects confidence values greater than specified. Min_length specifies the minimum number of items in each itemset while max_length specifies the maximum number of items in each itemset. I tried various min_support and min_confidence values and finalized on values that gave me data that made the most sense, while I specified min_length to be 2 and max_length to be 3, since there are only 3 different categories of variables from which associations can emerge. After defining the parameters, I applied the apriori() function to my ‘temp’ list of lists, and then applied the utility functions to the algorithm’s output to generate an ARM network graph.
Code
# Import necessary libraries import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom apyori import aprioriimport networkx as nx # Read datadf = pd.read_csv('../data/cleaned_wf_demo.csv', index_col=0)df['ethnicity'].unique()
## Clean and reformat data# Convert seniority column to string type since convert_to_network takes in string typedf['seniority'] = df.seniority.astype(str)# Select the columns we need into temporarly dataframestemp_1 = df['seniority']temp_2 = df['gender']temp_3 = df['ethnicity']# Reset index for both dataframestemp_1.reset_index(drop=True, inplace=True)temp_2.reset_index(drop=True, inplace=True)temp_3.reset_index(drop=True, inplace=True)# Initialize listtemp = [] # Create a list of lists of the data we needfor i inrange(0, len(temp_1)): x = [temp_1[i], temp_2[i], temp_3[i]] temp.append(x)# Check temp listtemp[7050:7070]
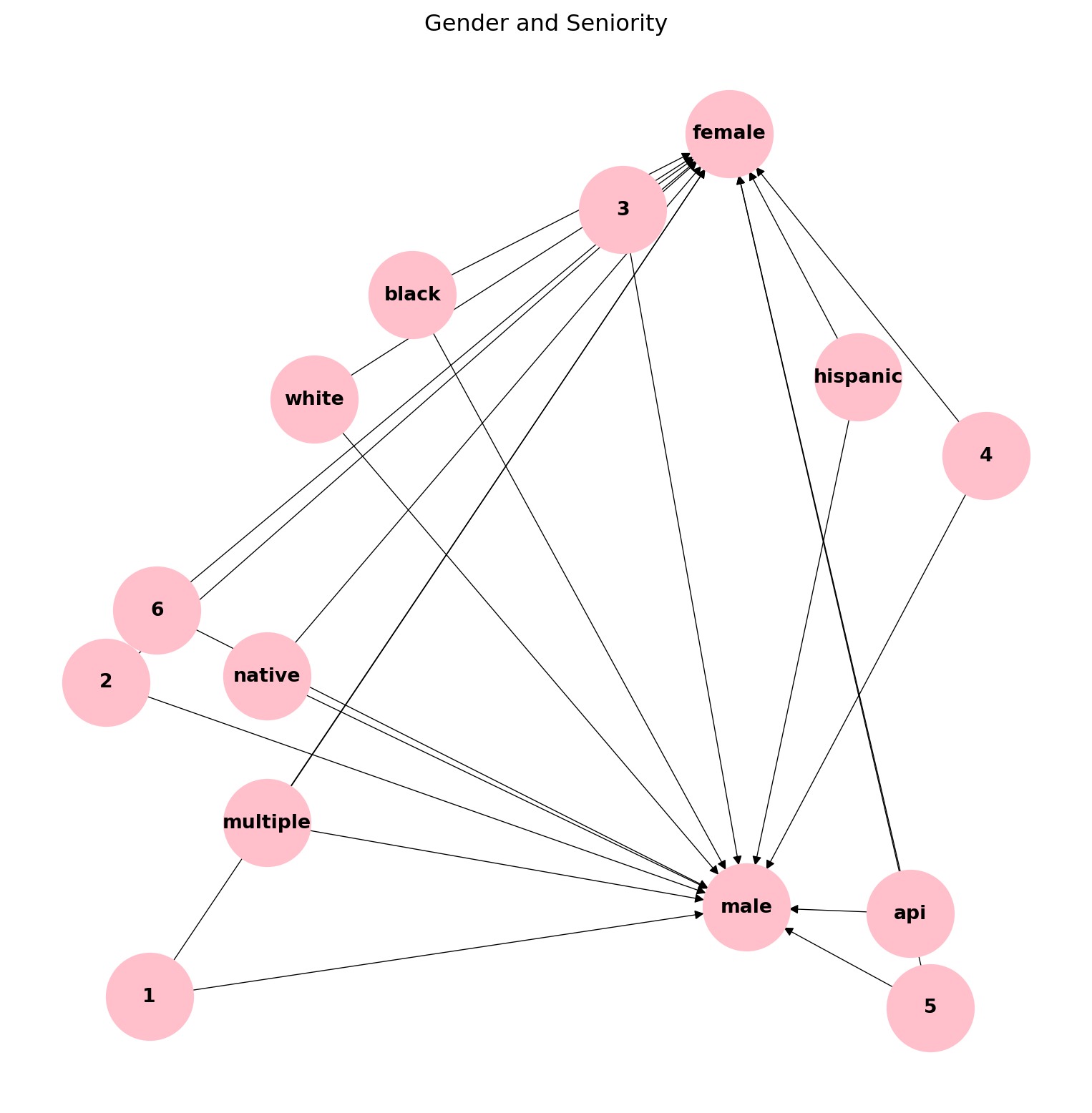
The results can be summarized in the following points: 1. Employees with either gender identity have strong associations with all ethnicity and job seniority categories. This means that there are no particular associations that are highlighted or revealing. This is confirmed with the generally consistent confidence and lift values. 2. Single-sided arrows in the network indicate that all associations are one-directional. That means that for any given association rule in the network, the other direction does not apply. For example, if we look at the association between male and 5, because the arrow is pointing from 5 to male, that means if someone is male then they have a job seniority of 5, but it does not that if someone has a job seniority of 5 then they are male. In particular, the arrows point towards gender, indicating “if” there’s a given ethnicity or job category, “then” there is an associated gender. 3. There are no associations between the gender categories, between the ethnicity categories, or between the seniority categories––this makes sense because each person can only take one value of each of these three groups.
5. Conclusion
In conclusion, it seems like ARM is not indicating any particular relationships between gender, ethnicity, and job seniority. This finding indicates that there may be other variables that I did not include in my features that affect seniority. If I had more time to conduct this analysis, I would examine other variables further to see if there are any associations. In particular, I would love to include company label, as past analyses in supervised ML algorithms showed me that there is a company-by-company variation in variables like seniority, ethnicity, and gender. Also, since I generated findings from incorporating variables like salary, inflow, and outflow, which cannot be included here since these are not categorical variables, ARM may not the most suitable algorithm for this dataset.
6. References
Edureka!. “Apriori Algorithm Explained | Association Rule Mining | Finding Frequent Itemset | Edureka.” YouTube, YouTube, 19 June 2019, https://www.youtube.com/watch?v=guVvtZ7ZClw.
Remanan, S. (2018, November 2). Association rule mining. Medium. Retrieved December 1, 2022, from https://towardsdatascience.com/association-rule-mining-be4122fc1793
Revelio Labs (2022, June 2). “FAQs” Revelio Labs Data Dictionary. Retrieved December 1, 2022, from https://www.data-dictionary.reveliolabs.com/faq.html
Garg, Anisha (2018, September 3). “Complete guide to Association Rules (1/2).” Medium. Retrieved December 1, 2022, from https://towardsdatascience.com/association-rules-2-aa9a77241654
Garg, Anisha (2018, September 17). “Complete guide to Association Rules (2/2).” Medium. Retrieved December 1, 2022, from https://towardsdatascience.com/complete-guide-to-association-rules-2-2-c92072b56c84